Llama 3 Powers Impressive Meta AI And It’s Accelerated On Intel Gaudi And Arc

Meta's Llama family of large language models are notable for remaining open source, despite being competitive in performance with the closed-source leaders, like the ironically-named OpenAI's GPT series and Google's Gemini family. The latest iteration of Llama is Llama 3, which comes in two versions: one with 8 billion parameters and one with 70 billion parameters.

Going off the benchmarks presented by Meta itself, the full 70B parameter version appears broadly competitive with OpenAI's GPT-4—even though that's not a comparison that Meta itself made. Instead, the company seems focused on comparisons with somewhat less popular rivals, including Google's Gemini and Gemma models and Anthropic's Claude 2, as well as the Mistral and Mixtral models from France's Mistral AI.
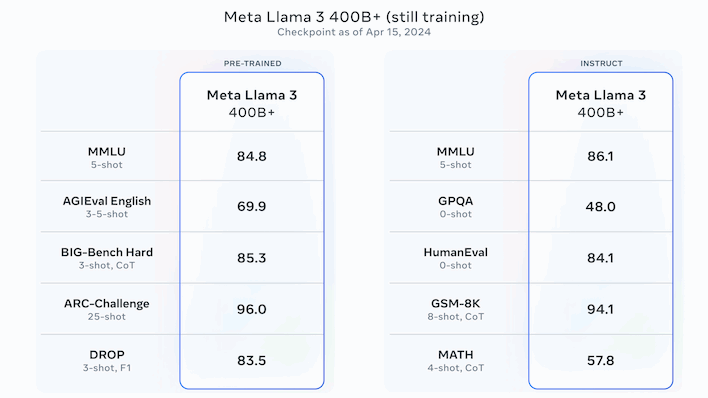
Overall, the numbers are compelling, but Meta isn't done working on its LLMs yet. Meta says that the largest version of Llama 3, with over 400 billion parameters, is still in training. The numbers above are for that model, and they're overall the best we've seen from what will presumably also be an open-source release. Meta says that Llama 3 will see additional releases "over the coming months" that add features like multimodality (images, audio, and maybe video), support for multiple languages, a longer context window, and more.
Notably, because Llama 3 is open-source, you can download the models right now and play with them locally. There is a caveat to that, though; you'll need to have a Bash environment set up, as the download requires the use of a shell script. This should be trivial for any AI researcher, most developers, and lots of power users, but if you're a casual AI enthusiast, you might be better off waiting for a more accessible package.
Indeed, this is all fine and good if you're an AI researcher, but what if you're a regular user? Well, you can (in theory) still try out Llama 3 using Meta's new Meta AI assistant. The assistant is built into the latest versions of the Facebook, Instagram, WhatsApp, and Messenger apps, where it can do things like recommend restaurants, find nightlife activities, assist with education, or generate images. It's also available to play with over at the new site, Meta.ai, although you'll need to bring a Facebook account to do anything interesting—and we weren't able to access the site even after logging in.
One downside of this restructure is that Meta's Imagine AI generation feature has been rolled into the new Meta AI site. Where previously it allowed users to login with Meta accounts, generating images now requires a Facebook account, likely to prevent anonymous users from slamming Meta's servers with compute-intensive image generation requests. However, it's learned some new tricks, including the ability to take created images and iterate on them, or even animate them, allowing users to share them with friends in GIF format. Very cool stuff.

Intel says that the Arc A770 is considerably faster than an RTX 4060 for large language models.
Intel's part in Meta's new AI endeavors behind the scenes isn't completely clear, but Intel is enthusiastic about them nonetheless. The company put out multiple releases and articles boasting of the high performance of its Core Ultra and Xeon CPUs, its Arc GPUs, and its Gaudi accelerators while running Llama 3.
In particular, the company notes that the integrated Arc GPU on a Core Ultra CPU can "already generate [text] faster than typical human reading speeds." Meanwhile, an eight-pack of Gaudi 2 chips can apparently generate some 131 sentences per second while doing a batch of ten prompts at once. Its upcoming Xeon 6 processors are seemingly twice as fast as Sapphire Rapids on Llama 3, too.
As far as Arc discrete GPUs go, Intel actually has an extended tutorial showing how to set up a large language model to run locally on your Arc GPU. We covered this back when Intel first showed it off, but the end result at this point seems considerably more user-friendly—even if the setup process is quite involved. If you have an Arc GPU and would like to chat with an LLM running directly on your PC, you can head over to Intel's guide for the walkthrough.