Intel 5th Gen Xeon Processors Debut: Emerald Rapids Benchmarks
Intel 5th Gen Xeon Scalable Benchmarks: General Compute Workloads

HotHardware's Server Test Setup
As with Genoa, we have chosen to use the Phoronix Test Suite because it offers both a wide variety of tests to choose from and for ease of reproducibility. For reference, we'd encourage you to visit openbenchmarking.org for additional information, reference numbers, and to compare your own existing infrastructure against these workloads, if you'd like.Coremark 1.0.1 Benchmark
We begin our testing with Coremark. Coremark is a quick, no-nonsense multi-threaded CPU test intended for basic comparisons.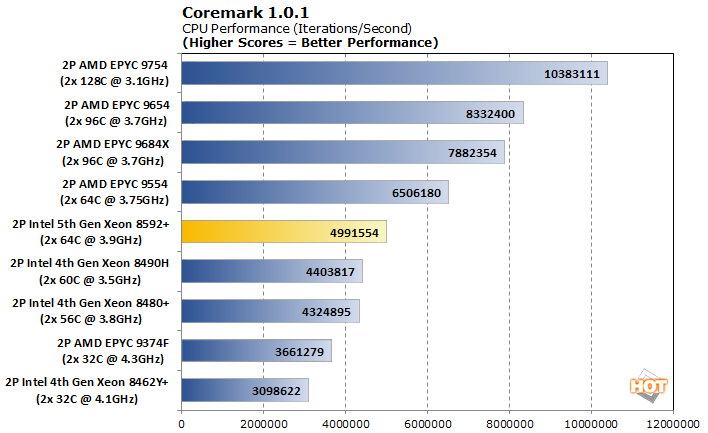
Coremark runs optimized, bare-metal algorithms for list find/sort operations, matrix manipulation, and CRC calculations, and other common functionality. With 7% more cores and around 10% extra clock speed, however, the latest generation of Xeon is about 13.4% faster than the Sapphire Rapids-based Xeon 8490H configuration. However, the benchmark has typically favored AMD's Genoa-based EPYC processors, and the latest from Intel is still about 50% slower in comparison to the 128 cores of our dual EPYC 9554 machine.
7-Zip 1.10.0 Compression/Decompression
Next, we looked at 7-Zip compression and decompression. The compression workload is influenced by memory and cache performance as well as out of order processing. Decompression is much more integer-driven, but also stresses the branch prediction pipeline.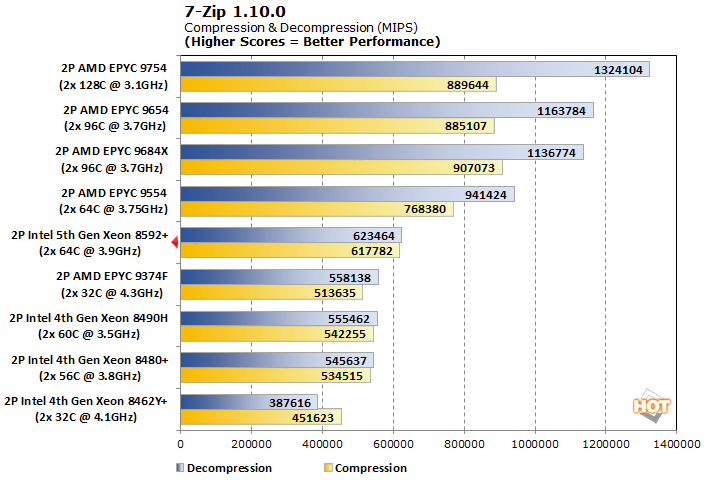
The 7-Zip workload shows a similar result, as our 5th-generation setup is about 13% faster than the previous generation. That's enough to boost past the dual EPYC 9374F system, but it's still far off the pace of the most direct comparison with EPYC 9554. Compression and decompression tasks are roughly equal in performance, where AMD's biggest advantage is in the decompression test.
Linux Kernel Compilation 1.15.0
Software compiling is a common task and building the Linux kernel itself has long been used as a performance benchmark. We tested with defconfig and allmodconfig with results reported in seconds.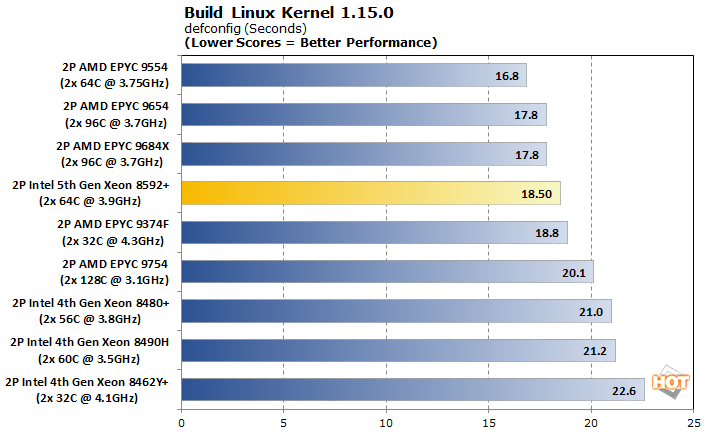
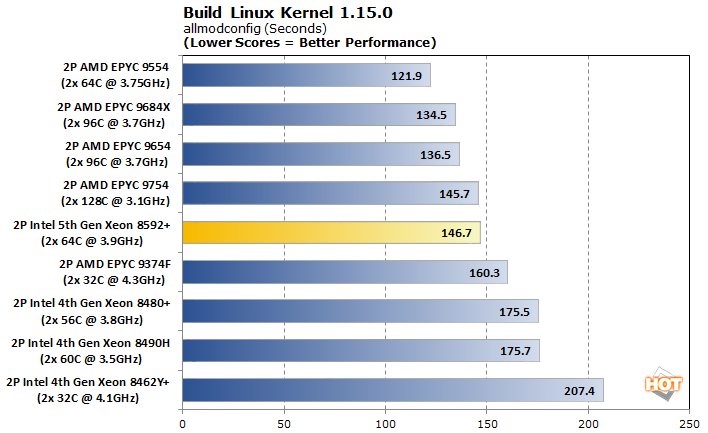
Kernel compilations get a big boost from Emerald Rapids, but both tests really just boil down to the core count. To a certain point, adding more cores and faster disk I/O can speed up compilations. However, when a job doesn't use all of the cores or incurs a latency penalty thanks to on-package interconnects, we can get some seemingly random results. We can see this at the top of both charts, where AMD's 64-core configuration reigns supreme over siblings with more cores. The default configuration is actually rather close between the two, with AMD sporting a mere 10% advantage.
There's a wider swing in the allmodconfig test, as this builds every part of the kernel as a loadable module, rather than one monolithic kernel. The 25-second difference between the fastest system, which is the 128-core EPYC 9554, and the 5th-generation Xeon Scalable setup equates to Intel being about 20% slower. This is closer than our previous tests, but still doesn't paint the latest from Intel in a great light. Emerald Rapids still represents a sizable 20% improvement over the previous generation, though.
Blender BMW 3.6.0 Model 3D Rendering
Blender is a staple 3D rendering benchmark. We queued up the tried and true BMW scene and gauged the time to render in seconds.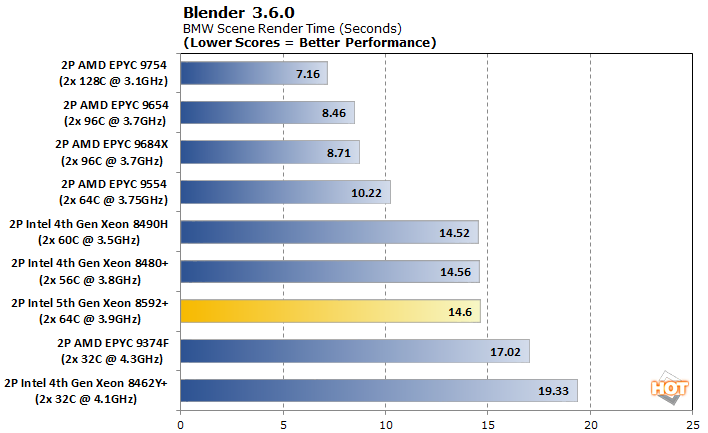
On AMD hardware, Blender shows a very distinct stairstep from one core count to the next. It's not a linear increase, but more is always better. With our Intel system, there is something else happening here. It could be an inter-core communication limitation, or perhaps a cache wall, but something is happening here that prevents Blender from running faster on our Emerald Rapids setup than anything but the 32C x 2 Sapphire Rapids 4th generation Xeons configuration. We hesitate to say that it's slower, although that's technically true; a couple hundredths of a second is close enough to say that it ties the previous generation, while AMD's processors just don't suffer from whatever quirk that Blender exposes here.
Embree 1.2.1 3D Rendering
Embree is a 3D path-tracing renderer which can leverage instruction sets like AVX2 and AVX512. The IPSC variant is compiled using the Intel Implicit SPMD Program Compiler which can see additional speedup when AVX acceleration is available.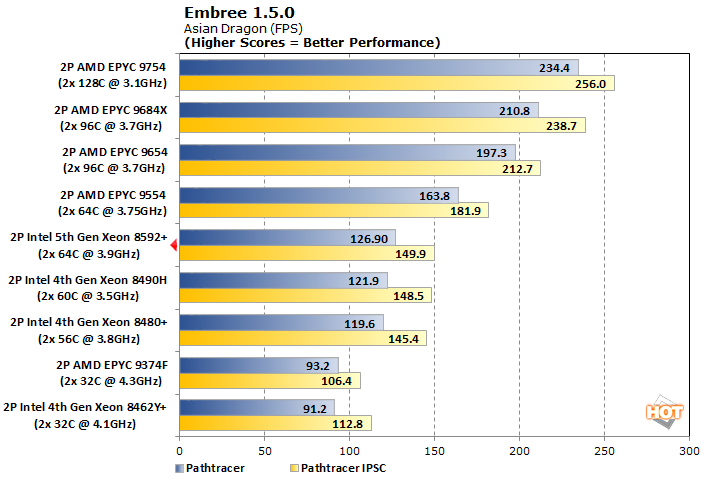
Embree has a similar issue to Blender with our Xeons. The IPSC-compiled version is close to 25% faster than the standard compiler for our Xeons, but the 5th generation Xeon 8592+ configuration doesn't run much faster than the generation that came before it. Once again, this is a clean win for AMD's 64-and-up crowd. Even the EPYC 9554 with a stock Pathtracer outpaces the IPSC version on Intel by about 10%.
POV-Ray 1.2.1 Ray Traced Rendering
POV-Ray, or the Persistence of Vision Ray-Tracer, is an open-source tool for creating realistically lit images. The Phoronix Test Suite implementation measures in time to complete, rather than the pixels-per-second we typically report in other reviews.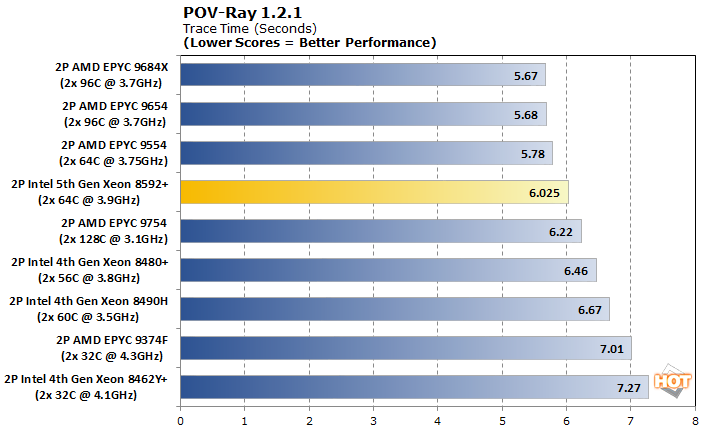
These POV-Ray results start to make sense again. Dual Xeon 8592+ processors can't quite catch the dual EPYC 9554 system, but they're within 5% of one another. It seems that going with more threads than a dual 64-core system doesn't make much sense here, as the 5th generation of Xeons sails right on past dual EPYC 9754 processors. It's likely that this test isn't using all of the threads available to it, or the workload is small enough that it doesn't need to do all that slicing.




