AMD Bergamo And Genoa-X Performance Review: EPYC Chips For Big Iron Workloads
AMD Bergamo And Genoa-X: AI And HPC Workloads, Final Thoughts And Conclusion

TensorFlow 2.0.0 Machine Learning Image Classification Benchmark
TensorFlow offers a few different models to analyze with, so we tested VGG-16, AlexNet, GoogLeNet, and ResNet-50 for pre-trained neural network image classification workloads.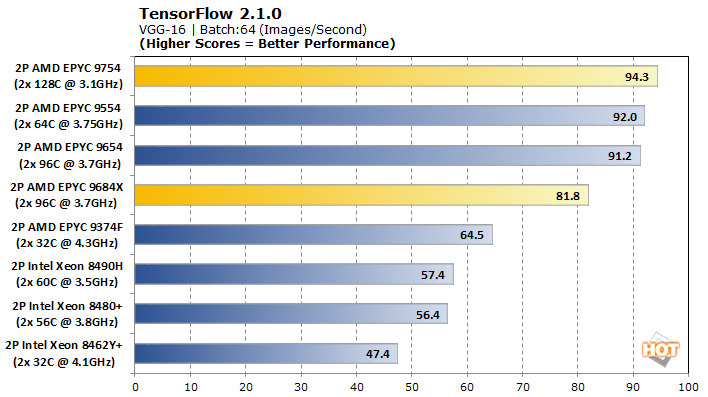

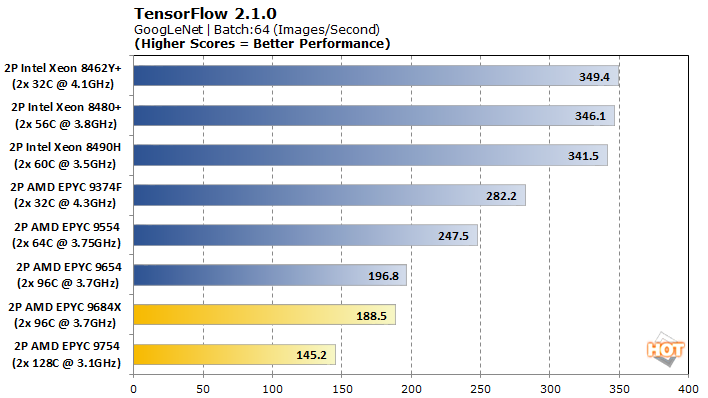
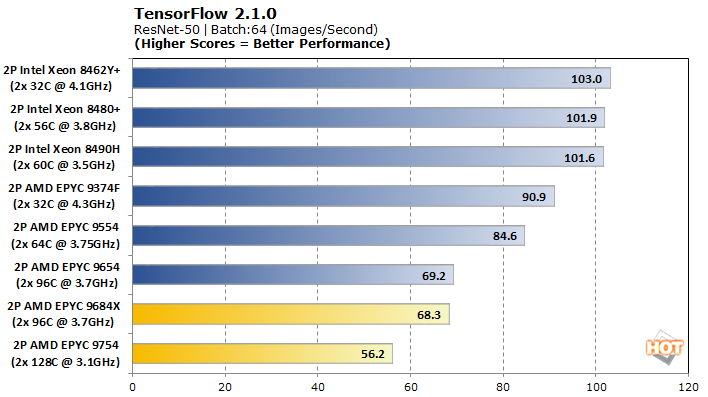
The EPYC 9754 narrowly claims the top spot in VGG-16, but the EPYC 9684X lags its Genoa counterpart. Unfortunately, that’s as good as TensorFlow gets for these chips, as the rest of the models drop the duo to the bottom of the stack, and Intel’s dedicated accelerators largely run away with performance in GoogLeNet and ResNet-50.
DeepSparse AI Inferencing 1.5.0 Benchmark
Neural Magic’s DeepSparse differs from many AI inferencing approaches, in that it is developed specifically for CPUs. As the name implies, the models are pruned extensively (e.g. sparsified) to deliver “GPU-Class” deep learning on CPUs while retaining a high degree of accuracy.

The EPYC 9754 performs particularly well in the asynchronous multi-stream text classification, with around 100 more items classified per second than the 96-core parts.


Moving to a synchronous-single stream stresses the cache more pushing the EPYC 9684X ahead while the reduced-cache Bergamo chip slides a few spots.
This is the other test where we’re borrowing a couple results from the Sapphire Rapids review. In this case, test versioning has changed so the Xeon 8462Y+ and EPYC 9374F results should be disregarded, but other chip’s scores between the two versions have held mostly constant none-the-less.
OneDNN 3.1.0 RNN Training And Inferencing Benchmark
OneDNN is an Intel-optimized open-source neural network library that is now part of oneAPI. Our testing looks at its performance in convolution, RNN training, and RNN inferencing across three data types: f32, u8u8f32, and bf16bf16bf16.


The EPYC 9684X performs about on par with the EPYC 9654 in all cases, which is to say near the bottom of the lineup. The EPYC 9754 scores even lower, making it not a particularly good fit for OneDNN workloads.
Embree 1.5.0 3D Rendering
Embree is a 3D path-tracing renderer which can leverage instruction sets like AVX2 and AVX512. The IPSC variant is compiled using the Intel Implicit SPMD Program Compiler which can see additional speedup when AVX acceleration is available.
Interestingly, the EPYC 9754 holds onto its top spot here but we also see the EPYC 9684X gap the EPYC 9654. This would suggest that cache is important to the path-tracing workload, but not so important that the Bergamo chip drops out of contention.
POV-Ray 1.2.1 Ray Traced Rendering
POV-Ray, or the Persistence of Vision Ray-Tracer, is an open-source tool for creating realistically lit images. The Phoronix Test Suite implementation measures in time to complete, rather than the pixels-per-second we typically report in other reviews.
The EPYC 9684X is again functionally equivalent to the EPYC 9654 here with results within the margin of error. The EPYC 9754 posts a decent result, though falls into the middle of the pack.
Intel Open Image Denoise 2.0.0 Benchmark
An important aspect of ray tracing is the denoising step which cleans up the image for a better-looking frame. Part of oneAPI, Intel Open Image Denoise is one such library to accomplish this which can be used not only for gaming, but also for animated features.
This workload takes great advantage of the threads Bergamo has on tap, lifting it to the top spot. Surprisingly, the EPYC 9684X falls quite a bit short of the EPYC 9654’s performance, and falls a few spots in the rankings.
ASKAP 2.1.0 Convolutional Resampling
The Australian Square Kilometre Array Pathfinder (ASKAP) is a massive radio telescope complex in Western Australia. It is tasked with processing enormous datasets including the tConvolve algorithm here which performs convolutional resampling.
This kind of HPC workload perfectly encapsulates the advantages 3D V-Cache can afford. The EPYC 9684X is 49-52% faster in these tasks than the Genoa EPYC 9654 and absolutely dwarfs the performance of the Xeon processors.
Monte Carlo Simulations Of Ionized Nebulae 1.1.0
Monte Carlo simulations pop up in a variety of fields ranging from physics and computational fluid dynamics to financial market analysis. These use a series of random samplings as inputs to figure out probability distributions, estimating possible outcomes.

The MOCASSIN benchmark favors lower core counts, presumably due to reduced inter-core latency. As a result, neither the Bergamo nor Genoa-X chips are top contenders here.
OpenFOAM 1.2.0 Computational Fluid Dynamics
OpenFOAM is a free and open-source computational fluid dynamics program from the OpenFOAM foundation. We tested two aerodynamics models, the smaller-scale motorBike and the large-scale drivaerFastback.

Starting with motorBike, the mesh times are favored on the lower core-count chips. However, the execution time can be the bigger bottleneck, and we see the EPYC 9684X nearly jump into the lead.
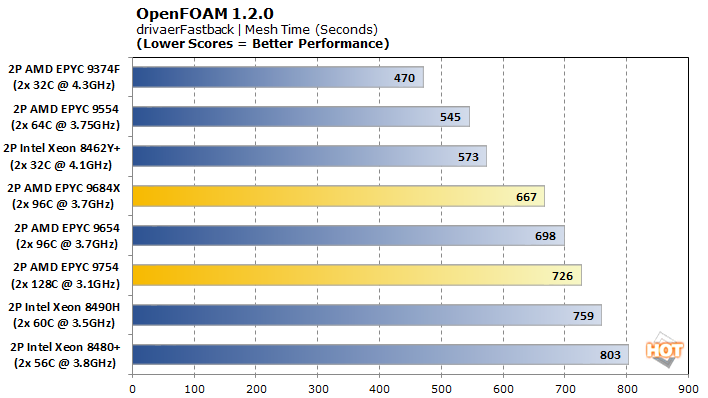
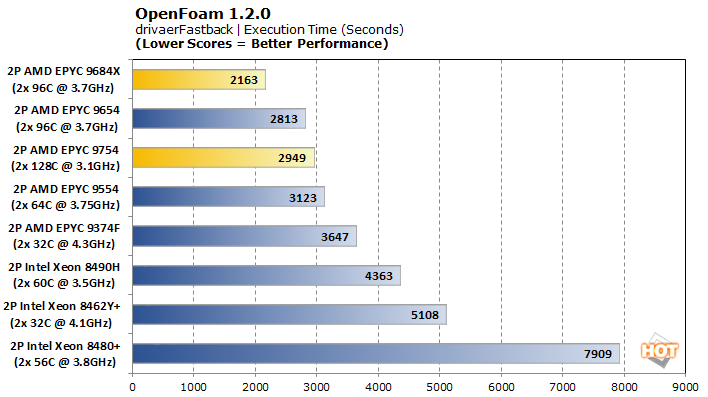
With a significantly larger model in drivaerFastback, the AMD EPYC 9684X takes the top spot for execution time uncontested, besting the EPYC 9654 by around 30%. The EPYC 9754 is no slouch here, either, slotting into third place. Again, mesh times are more mixed, but that only represents a fraction of the overall workload.
LAMMPS 1.4.0 Large Scale Atomic Simulation
The Large-scale Atomic/Molecular Massively Parallel Simulator is widely used for materials modeling in a range of fields, thanks in part to its open-source availability. This enables it to be adapted to all kinds of hardware and to be modified for new functionality.
The Bergamo chip is able to edge out the EPYC 9654 for the top spot, by not by much. The EPYC 9684X holds on to third place by a hair, but really trades blows with the 64-core Genoa EPYC 9554.
AMD Genoa-X And Bergamo Performance: Final Thoughts And Key Take-Aways
AMD came out swinging with Genoa, which went toe to toe with Intel's Xeon Scalable Processor platform and emerged victorious, at least as far as general compute workloads are concerned. Sapphire Rapids brought an asymmetrical approach with a bevy of dedicated accelerators to counterpunch in particular specialized workloads, though, especially in the AI space.
These new specialized AMD server processors take a decidedly more conservative approach. AMD is not relying on fixed-function accelerators for its magic, but rather optimizations of the core Genoa DNA to better suit particular use cases. Case in point, the Genoa-X EPYC 9684X mirrors or even narrowly trails the Genoa EPYC 9654 in most workloads. However, in its HPC and 3D render niche (e.g. ASKAP, Embree, OpenFOAM), the extra cache allows the Genoa-X processor to outpace its Genoa counterpart by as much as 50% and leave Intel well behind.

Bergamo has more radical departures from Genoa, but its Zen 4 DNA is still present all the same. The Zen 4c architecture sheds some L3 cache and clock speeds but gains a significant amount of core density per socket that is very appealing to hyperscalers deploying cloud-native applications. These qualities allow Bergamo to be a top performer in raw compute scenarios, ranging from Coremark and 7-Zip decompression to Blender and even LAMMPS. Its workload-to-workload results are more hit-or-miss than the general-purpose Genoa chips, however. For every workload it tops the chart in, there's another like DaCapo, NGINX, OneDNN, or Tensorflow where it trails. These trade-offs are of little consequence to their intended hyperscaler customers, however.
AMD's Zen 4 EPYC processors have several less tangible, but highly attractive qualities as well. The chips all share the same SP5 platform with very similar physical properties and interfaces. This can allow customers that started with Genoa to swap in Genoa-X or Bergamo chips to suit their needs without having to fully rearchitect servers. Customers do not need to optimize any software or acquire special licensing to leverage them, either.
These processors are not intended to be jacks-of-all-trades; they have specialized roles and are well-suited to them. While good ol' Genoa still holds its own across most workloads out there, Bergamo and Genoa-X can feel like they're unlocking cloud and HPC cheat codes under the right conditions. Of course, the same can be said for Intel's Sapphire Rapids fixed function accelerators, but as of yet these optimizations are chasing slightly different markets. In any case, if you're in IT, do your homework to select the solution that makes sense for your datacenter applications and workloads.





