How To Run ChatGPT-Like AI On GeForce RTX Cards Using NVIDIA Chat With RTX
There are lots of caveats to these cloud-hosted AI models. Even as a casual user, the delay before they respond can be annoying, and trying to integrate these services with your own data to make use of their skills can be a tiresome task in and of itself. You can get around a lot of the limitations of cloud-based AI by hosting it locally, but this has been a challenge with language models as they tend to be extremely large.
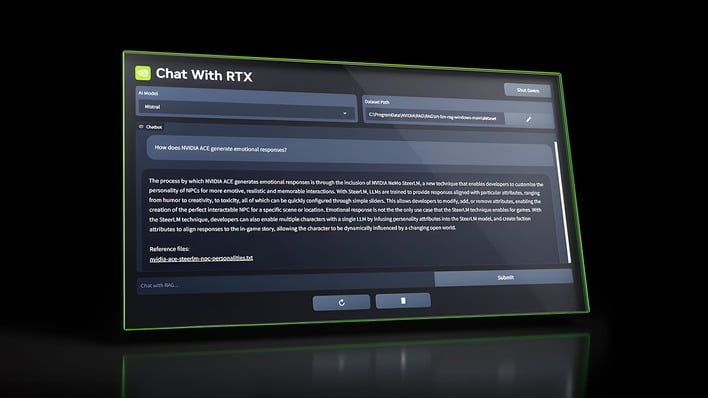
It's entirely possible, though, and NVIDIA has decided to put together a demo that shows this off. In the new Chat with RTX Demo, downloadable from NVIDIA's website, you can click one icon and open a locally-hosted web application that lets you chat with a language model directly in your browser. The demo comes with Mistral 7B and Llama 2 13B, both in INT4 format, but you can actually install your own TensorRT-LLM-compatible models as well.
That's because Chat with RTX is hosted right on your own PC, and runs on your machine's GeForce GPU. In turn, that means that there's no network latency, and also no chance for anyone to snoop on your chat, either. You can feed the app a folder of documents in text, PDF, docx, or XML format and it can reference the data and perform analysis on it for you. You can also point it at a YouTube video or playlist to have it download the transcripts and summarize them for you.
Obviously, this requires a reasonably beefy setup. You'll need at least 16GB of system RAM, a GeForce RTX 30 or RTX 40 series card with at least 8GB of video RAM, and a recent version of Windows 10 or Windows 11. You'll need GeForce driver 535.11 or newer, and you're also going to need about 65GB of disk space once the app is installed. The download itself is some 35GB in size, and the whole download and install process took about an hour and a half on our Ryzen 7 5800X3D machine—most of which was the install.
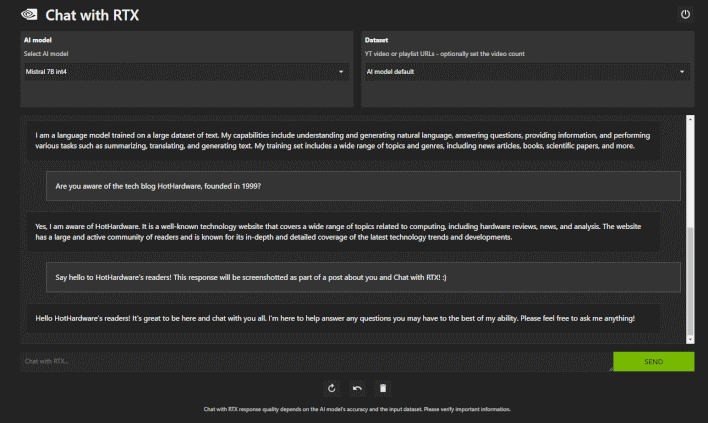
The biggest issue with the Chat With RTX demo right now is that it doesn't preserve context. What this means is that every single query to the language model you've selected is treated as a new conversation, and it can't reference previous queries for analysis. It's still potentially useful for analysis of datasets or summarizing YouTube videos, but this critical missing feature does make it less interesting as a conversation partner, at least for now.
If you'd like to see what an LLM can do for your dataset, head over to the NVIDIA website to grab Chat with RTX and give it a try. Just be mindful of the requirements we noted above.