big.LITTLE: ARM's Strategy For Efficient Computing
Introduction.
In Part I of this series, we discussed ARM's business model and how it works with its various partners as compared to Intel. Today, we're diving into a specific technology that ARM believes will allow it to differentiate its products and offer superior performance to Santa Clara and the upcoming 22nm Bay Trail.
big.LITTLE is ARM's solution to a particularly nasty problem: New process nodes no longer deliver the kind of overall power consumption improvements that they did prior to 2005. Prior to 90nm, semiconductor firms could count on new chips being smaller, faster, and drawing less power at a given frequency. Eight years ago, that stopped being true. Tighter process geometries still pack more transistors per square millimeter, but the improvements to power consumption and maximum frequency have been falling every single node. Rising defect densities have already created a situation where -- for the first time ever -- 20nm chips won't be cheaper than the 28nm processors they're supposed to replace. This is a critical problem for mobile, where low power consumption is absolutely vital.
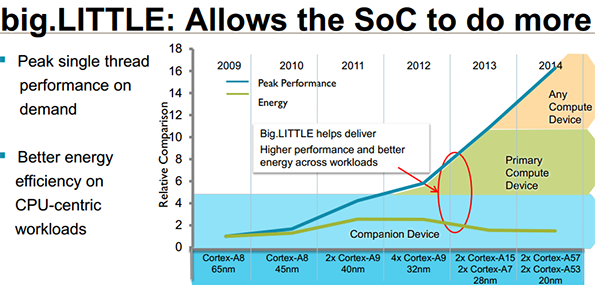
big.LITTLE is ARM's answer to this problem. The strategy requires manufacturers to implement two sets of cores -- the Cortex-A7 and Cortex-A15 is the current match-up, though long term, a wide variety of options are possible. The idea is for the little cores to handle the bulk of the phone's work, with the big cores used for occasional heavy lifting. ARM's argument is that this approach is superior to dynamic voltage and frequency scaling (DVFS) because it's impossible for a single CPU architecture to retain a linear performance/power curve across its entire frequency range. This is the same argument Nvidia made when it built the Companion Core in Tegra 3.
In theory, this gives you the best of both worlds. Actual implementation, unfortunately, has proven to be a bit more complicated.
Implementing big.LITTLE in Software:

There are three ways to build a big.LITTLE design. The first and simplest is cluster migration. When load on one cluster hits a certain point, the system transitions to the other cluster. All relevant data is passed through the common L2 cache, one set of cores powers down, and the other powers up. This is transparent to the OS, which always sees just four cores. The problem with this approach is that a poorly tuned scehduler can leave substantial power savings on the table. If the big A15 cores wake up too early, workloads that could have run on the low-power Cortex-A7's end up on the A15's.
The second model is CPU migration. In this model, each big core is virtually paired with a little counterpart. If the system detects a high load on LITTLE CPU 0 (A7) it ramps up big CPU 0 (A15) and moves the workload over to the larger core. Again, no more than four cores are active at any given time, but this allows for fine-grained control.
The third model is the long-term goal: A global task scheduler. This requires an intelligent software scheduler that sees all cores simultaneously, understands which workloads are best suited to run on which cores, and can schedule them appropriately. Combined with HSA, this allows the system to maximize performance in virtually any workload. It takes less time to transfer data between cores and it's possible to build non-symmetric processor layouts. This last one is a crucial feature. In the first two types of big.LITTLE designs, cores must be implemented 1:1, with one A15 for every A7 and vice versa. A Global Task Scheduler frees this constraint
Click to embiggen
The advantage to a global task scheduler is that you no longer take a mandatory hit when switching between clusters (it takes a non-zero amount of time to transfer data) and you can use all cores simultaneously. Unlike cluster and CPU migration configurations, a global scheduler can use asymmetric ARM configurations. Want a quad-core Cortex-A7 with a dual-core A15? You can have that. Want an A5, two A7's, and one A15? You could have that, too.
big.LITTLE is ARM's solution to a particularly nasty problem: New process nodes no longer deliver the kind of overall power consumption improvements that they did prior to 2005. Prior to 90nm, semiconductor firms could count on new chips being smaller, faster, and drawing less power at a given frequency. Eight years ago, that stopped being true. Tighter process geometries still pack more transistors per square millimeter, but the improvements to power consumption and maximum frequency have been falling every single node. Rising defect densities have already created a situation where -- for the first time ever -- 20nm chips won't be cheaper than the 28nm processors they're supposed to replace. This is a critical problem for mobile, where low power consumption is absolutely vital.
big.LITTLE is ARM's answer to this problem. The strategy requires manufacturers to implement two sets of cores -- the Cortex-A7 and Cortex-A15 is the current match-up, though long term, a wide variety of options are possible. The idea is for the little cores to handle the bulk of the phone's work, with the big cores used for occasional heavy lifting. ARM's argument is that this approach is superior to dynamic voltage and frequency scaling (DVFS) because it's impossible for a single CPU architecture to retain a linear performance/power curve across its entire frequency range. This is the same argument Nvidia made when it built the Companion Core in Tegra 3.
In theory, this gives you the best of both worlds. Actual implementation, unfortunately, has proven to be a bit more complicated.
Implementing big.LITTLE in Software:

There are three ways to build a big.LITTLE design. The first and simplest is cluster migration. When load on one cluster hits a certain point, the system transitions to the other cluster. All relevant data is passed through the common L2 cache, one set of cores powers down, and the other powers up. This is transparent to the OS, which always sees just four cores. The problem with this approach is that a poorly tuned scehduler can leave substantial power savings on the table. If the big A15 cores wake up too early, workloads that could have run on the low-power Cortex-A7's end up on the A15's.
The second model is CPU migration. In this model, each big core is virtually paired with a little counterpart. If the system detects a high load on LITTLE CPU 0 (A7) it ramps up big CPU 0 (A15) and moves the workload over to the larger core. Again, no more than four cores are active at any given time, but this allows for fine-grained control.
The third model is the long-term goal: A global task scheduler. This requires an intelligent software scheduler that sees all cores simultaneously, understands which workloads are best suited to run on which cores, and can schedule them appropriately. Combined with HSA, this allows the system to maximize performance in virtually any workload. It takes less time to transfer data between cores and it's possible to build non-symmetric processor layouts. This last one is a crucial feature. In the first two types of big.LITTLE designs, cores must be implemented 1:1, with one A15 for every A7 and vice versa. A Global Task Scheduler frees this constraint
;)
Click to embiggen
The advantage to a global task scheduler is that you no longer take a mandatory hit when switching between clusters (it takes a non-zero amount of time to transfer data) and you can use all cores simultaneously. Unlike cluster and CPU migration configurations, a global scheduler can use asymmetric ARM configurations. Want a quad-core Cortex-A7 with a dual-core A15? You can have that. Want an A5, two A7's, and one A15? You could have that, too.




